Local Intelligence, an Important Step in the Future of MAD (Mass AI Deployment)
 TBA
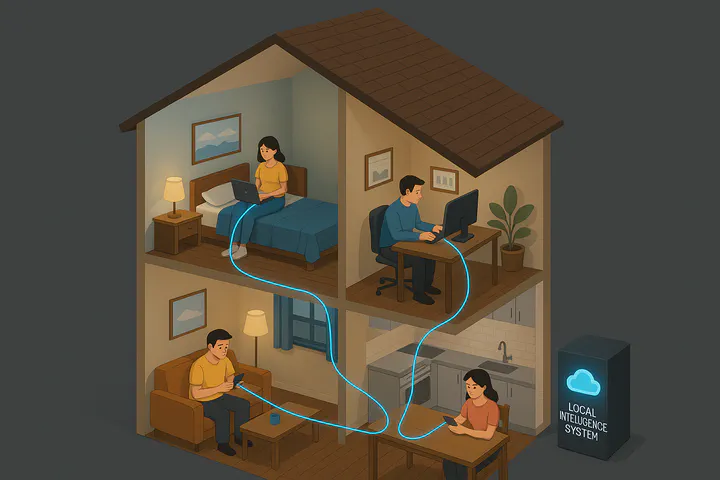
TBAIt is not artificial intelligence; it is not apple intelligence. It is at-your-service intelligence.
Why local Intelligence?
Have you ever found yourself in a situation where your internet connection suddenly drops, or your favorite AI service refuses to work, leaving you stranded in the middle of an important task? It’s frustrating, isn’t it? Now, imagine if you had a local intelligence system that kept running smoothly, allowing you to continue working without a hitch. This is just one of the many reasons why local intelligence is worth considering, especially our work is increasingly reliant on machine intelligence.
You might wonder, with so many state of the art AI tools available through apps and cloud services, why would anyone bother setting up a local system? It seems like a complicated endeavor, right? But let’s explore some compelling benefits that might just change your mind.
First and foremost, let’s talk about resilience. When the internet goes down, a local intelligence system remains operational. This resilience is particularly valuable for individuals or small businesses who rely on continuous access to large language models for daily tasks such as content creation, coding and problem solving. Think of it like having your own backup generator for electricity, or a personal reservoir for water. While it’s not always practical or cost-effective to maintain your own utilities, depending on where you live, having that option can provide peace of mind.
Now, local intelligence doesn’t mean you have to go completely off the grid. Instead, it’s about creating an integrated system that works seamlessly in your home or business. Rather than juggling multiple cloud-based services, a local intelligence consolidates everything together. It leverages local processing power to increase response time, and it configures services like speech recognition, generation and visual processing for the majority of users so that it “just works” for them.
Another significant advantage of local intelligence is the ability to monitor usage effectively. A local intelligence system can provide detailed analytics on how it is being utilized, offering insights into user behavior, preferences, and areas for improvement. Imagine having a tool that not only performs tasks but also provides insights into how you and your team are using it. You may also notice your kids are using the wrong AI to help them with their math problems. This kind of analytics can reveal user preferences and highlight areas for improvement. By analyzing which features are most frequently accessed, businesses can prioritize updates and enhancements that align with user demands. Needless to say, this also provides a level of data security and privacy that is increasingly important in today’s digital landscape.
One of the less explored but truly exciting benefits of a local intelligence system is its potential to be the heart of a smart home. While today’s idea of a smart home may seem advanced, it’s actually quite basic in the era of AI. If being “smart” is merely about having a few devices that can be controlled by voice or a computer, along with some preset routines, then just wait! The next generation of smart homes, fueled by local intelligence systems, is set to take things to a whole new level.
Finally, let’s not forget about costs. Text-to-Speech (TTS) and Speech-to-Text (STT) technologies are fantastic for improving accessibility and user interaction, but they can also add up quickly when relying on cloud services that charge based on usage. A local intelligence system can provide these capabilities in-house, allowing you to manage your budget more effectively while still delivering high-quality audio and transcription services. This cost efficiency can free up resources for other critical areas of your operations.
Looking to the future, the landscape of AI is evolving rapidly. We’re definitely moving beyond just chatbots that reside on your browser tabs. AI is permeating every corner of our workflow, whether it is creative or mundane tasks. We seek to transfer not only we hear, we see but also what we can do to AI. Some of the audiovisual processing demonstrations from companies like OpenAI and Google already indicated the huge potential in applying AI many many times more pervasive that it currently is. However, implementing these capabilities in a cloud-based service will be demanding to the internet infrastructure and server capacity. A local intelligence system may be better idea for a responsive system.
Let’s be clear: a local intelligence system isn’t necessarily a better solution than cloud services; it’s a different kind. It’s a comprehensive approach that integrates various functionalities tailored to meet specific needs. I believe that most small businesses and families will find value to implement a local intelligence system. From ensuring uninterrupted service during outages to providing valuable insights, managing costs, and exploring the future of audiovisual capabilities, a local intelligence system can be a critical step in the future of mass AI deployment.
After all, the future of AI is not just in the cloud; it’s also right at home.
An Overview of How Things Work
As I sit down to write this on May 9, 2025, I can see the vision taking shape, even if not all the pieces are quite in place yet.
Imagine a local intelligence system built on a client-server architecture that brings together several key components:
The Hardware: At the heart of this system is a dedicated machine running a large language model (LLM) server, equipped with ample VRAM (or unified memory, as it’s known on Macs, shared between the GPU and CPU).
The Software: We’ll need a specialized piece of software to load the LLM and handle inference. Options like Ollama, LM Studio, or any future innovations will do the trick. This software must be designed for maximum resource efficiency, as it’s likely to be the bottleneck for all users on the network.
The Middleman: Enter solutions like Open WebUI, LobeChat, and LibreChat. These platforms act as the bridge between the LLM server and the multitude of clients on the network. Here, we’ll see service consolidation and integration in action. Most of these systems support local LLMs while also providing API access to cloud platforms. To keep things flexible, we can add audiovisual enhancements as extensions. The market is bustling with various providers, some free and others paid, allowing us to cater to a wide range of user needs.
The Clients on Your LAN: Whether they’re running on Mac, Windows, or Linux, and whether they’re desktops or mobile devices, our clients will have a universal access point through a web-based solution. The local intelligence system will have its own dedicated local IP address and port, allowing every client to connect. Of course, this approach does come with its own set of security challenges, especially when it comes to media control.
My Test Setup
My server is a Mac mini M4 pro with 48GB memory. It is certainly not the base model but I believe this amount of memory is necessary to run a model with some ancillary services.
A common approach to running LLM server and a multitude of media services is to use docker. However I did not use the official docker app and instead went for OrbStack for efficiency.
With OrbStack installed, the efficiency of running docker become acceptable. At first I looked into new models in Ollama, and I downloaded Gemma3 27b, which required about 20GB of memory. While the speed is still a bit sluggish, there’s a glimmer of hope on the horizon! If Ollama supports MLX models (which is currently in progress), we could see a 40% performance boost. Just imagine if the speed were to double—it would become almost usable!
This naturally brings us to LM Studio, which, as far as I know, is currently the only solution that supports MLX. During my tests with Qwen3 30b 4bit, I achieved a respectable 73.46 tok/sec, which is quite decent for everyday use. LM Studio is a comprehensive solution that includes both a desktop UI and a server, and its backend can also be utilized by others. While I’m not entirely sure about the overhead, in terms of ease of use, it definitely outshines Ollama. The admin interface is user-friendly and makes it crystal clear what’s happening, allowing you to see all incoming requests—super helpful for diagnosing any issues.
Time to implement the infrastructure between the LLM server and network clients. I tested OpenWeb UI a while back, and I admit I didn’t fully grasp its purpose. The concept of having a server running with a frontend in a web browser seemed unnecessary at first. But now it all makes sense! The backend essentially acts as a middleman between the frontend functionalities and the API calls to LLM servers like Ollama and LM Studio. The reason for separating the frontend is that you can access it from any device, anywhere, using a browser.
It also supports multiple accounts, making it ideal for family use. The admin can control the settings while regular users can simply do what they need.
Now, the last bit of amazing feature is the built-in voice chatting feature, inside a browser. It will listen to your input, automatically detect the pause, generate the response, and use TTS for the result.
Adding LLMs
Open WebUI (OWU) is designed to seamlessly integrate with OpenAI and the OpenAI-compatible API. If you’re using OpenAI, all you need to do is enter your API key, and you’re good to go!
For those utilizing Ollama, there’s a dedicated section just for you, so be sure to check that out. Now, if you’re like me and prefer using LM Studio, make sure your base URL includes “v1.” You can easily add this under the OpenAI API section instead of the Ollama section. For example, you would use something like http://host.docker.internal:1234/v1.
When it comes to other vendors, the situation varies. Google is quite straightforward; you can simply use the OpenAI-compatible API for Gemini. However, for Anthropic models, things get a bit more complex. You’ll need to install a function called Anthropic Manifold Pipe and paste in your API key.
In my view, there’s definitely room for improvement in this area. OWU doesn’t quite measure up to some of those BYOA (Bring Your Own API) products.
One feature that would be incredibly beneficial is the ability to monitor usage by models or users. It would be great to know which model is a favorite for a particular user and to track their usage patterns. I believe this is already on the roadmap, and I can easily see it becoming a valuable paid feature in the future!
STT and TTS
STT (Speech to Text) and TTS (Text to Speech) may share some similarities, but their user requirements are quite distinct. When it comes to STT, response time is crucial—nobody wants to wait more than a second for their transcription! Accuracy is also a key factor.
On the flip side, TTS can afford to have a bit of delay since playback takes time. The real challenge here is to make the speech sound natural and engaging.
For speech recognition, the whisper model is supported and comes included with the base model, which is already a significant improvement over Siri. If you’re looking for an even higher recognition rate, you can download the large-v3 model, or consider the distil-large-v3, which is 6.3 times faster. However, I found that the distilled model doesn’t work well with Chinese.
If budget isn’t a concern, the gpt-4o-mini-transcribe is an excellent option. It performs admirably in both languages, with a consistent response time of about 3 seconds. While this might feel a bit lengthy, I’m optimistic that I’ll eventually find a local model that meets my needs for both responsiveness and accuracy. As for costs, it’s quite reasonable at $0.003 per minute of audio, meaning transcribing an hour (60 minutes) would set you back just $0.18.
There are some great free options available for text-to-speech (TTS). I’ve had the chance to test both Edge TTS and Kokoro, which are mentioned in the official OWU documentation. Both can be run as separate containers on the same server, making them quite convenient. Kokoro is an open-source solution that performs admirably in English, but its Chinese pronunciation leaves something to be desired—it sounds more like a Japanese speaker trying to speak Chinese. This is likely due to the training data it was built on. So far, the only platform I know of that offers usable Chinese voices is Microsoft Azure’s voice gallery, which is utilized by Edge TTS.
There’s also an exciting new generation of TTS that can convey emotions, like Orpheus. While I haven’t tested it myself, I’ve seen some impressive demonstrations. To fully harness its capabilities, you’ll need a custom model output that injects emotion tags.
Since these models are trained on different datasets and no single model can perfectly handle all languages, a highly desirable feature would be the ability to switch models based on the detected language. This isn’t too challenging—I created an Obsidian plugin that does just that.
Ultimately, our goal is to achieve the experience of a true multilingual speaker who can effortlessly switch between languages with native accents. Recently, I had the opportunity to try out Meta AI’s conversational agent, and I was pleasantly surprised to discover that it can speak several European languages—like French, Italian, and Spanish—with a perfectly native accent. However, when it comes to East Asian languages, it is still a no-no.
Web Search & Image generation
Web search is essential when it comes to using LLMs. Without web search current LLMs all tend to hallucinate. It seems that OWU requires APIs for everything—think Tavily, Brave, and more. The setup is quite straightforward, but there’s definitely room for optimization in terms of efficiency (just look at Dia for comparison!).
Now, let’s talk about image generation. To truly make it a core component of a local intelligence system, we need better models and significantly improved usability for end-users. The potential for enhancement in this area is enormous!
So, what’s currently available? I’ve managed to get Gemini 2.0 up and running, but I have to say, the image quality leaves much to be desired. As for OpenAI, only the DALL-E models are natively supported by OWU. If you want to use the gpt-image-1 model, you’ll need to rely on a community plugin. The cost per image with OpenAI’s gpt-image-1 model varies based on the quality you choose: approximately $0.02 for low quality, $0.07 for medium, and $0.19 for high quality for a square image. It’s not going to break the bank, but it’s also not quite ready for endless fun just yet.
Once the technology matures, I suspect this will become one of the most heavily utilized features of our local intelligence system—just imagine everyone on their phones, endlessly tweaking their photos!