To Think or not to Think - How “Reasoning” in LLMs Evolved
 TBA
TBA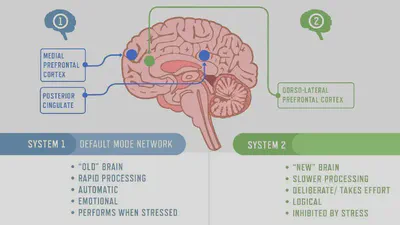
Reasoning in large language models represents an important shift in artificial intelligence—from instant responses to deliberate problem-solving. This evolution mirrors a profound insight from cognitive psychology: Daniel Kahneman’s theory of System 1 and System 2 thinking, which has become the philosophical backbone of recent AI reasoning research. System 1, in Kahneman’s framework, operates automatically and quickly, with little effort and no sense of voluntary control—recognizing a face, driving without much thinking, avoiding obstacle when walking etc. System 2, by contrast, allocates attention to effortful mental activities that demand it, including complex computations and deliberate reasoning—writing, solving math problems, making hard decisions etc.
The situation is very much paralleled in LLM development. The first generation of LLMs generate immediate, pattern-based responses. They immediately start to churn out tokens as soon as you ask your questions. In contrast, reasoning or “thinking” models will go through a thinking phase to understand the question in depth, make plans, explore different alternatives, and verify intermediary results. In many situations, thinking will significantly “boost” the performance of the LLM.
Further Reading: The Hierarchical Reasoning Model Through the Lens of Quaternion Process Theory: Thinking Fast and Slow, Empathetically and Fluently
How does the reasoning work? In what ways can this feature be implemented? What are its current limitations? What will the role reasoning plays in the future of LLM evolution? This article aims to tackle these questions and provide an in-depth yet non-technical investigation.
Prompting for Reasoning
How to teach machines to switch from their natural System 1 mode (fast, intuitive, but sometimes wrong) to System 2 mode (slow, deliberate, more accurate) when the situation demands it? There are easy ways and there are more complicated ways.
Just as humans can be prompted to engage System 2 thinking by being asked to “think step by step” or “check your work,” early approaches to LLM reasoning relied on prompting strategies. In the system prompt of some models, there exist “trigger words” which will instruct the model to go through greater length when these words are present in the user prompt. Chain-of-Thought prompting asks the model to show its work step-by-step. Tree-of-Thought creates branching paths of possibilities, like a chess player considering multiple moves ahead. Critic loops act as internal editors, generating ideas then refining them iteratively.
While this approach works as a sort of open secret, not every user is aware of it. In everyday use, users tend to put in simple prompts first and only resort to using trigger words when the result is unsatisfactory. This back and forth process obviously leaves something to be desired. Hence the challenge has been creating models that, like the human mind, can recognize when to shift gears—knowing when a quick System 1 response suffices and when to engage the more demanding but more reliable System 2 processing. Prompting for reasoning can still exist to nudge the LLM to think harder, but a mechanism to do so autonomously is definitely necessary.
(Half)Baked-in Reasoning
OpenAI’s “o” series models (unfortunately named, given they also have a model called “4o” where “o” means something entirely different) marked an important moment where reasoning became a baked-in feature. Rather than coaxing reasoning through clever prompting, these models have reasoning always enabled. This is done through specialized training on complex problem-solving datasets and reinforcement learning that rewards systematic thinking.
Further Reading: OpenAI explains reasoning in o1 Notice how the reasoning capabilities increased dramatically compared to the prompting approach by successfully decoding the ciphertext as follows:
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
If previously we have to beg AI to think harder and longer to produce better results; now we have the choice to talk to someone who naturally thinks systematically. Call this person a “nerd philosopher” as compared to a “regular guy” who prefers talking over thinking. While the responsibility still rests with the user to choose the right model for the task at hand, you no longer have to rely on trigger words and cross your fingers, hoping AI will tackle your question effectively. In addition, as the reasoning is reinforced in the pre-training stage the result is better.
These reasoning models excel at complex challenges—the kinds measured by benchmarks like “Humanity’s Last Exam” and advanced mathematics competitions such as AIME. Yet they can be comically inappropriate for simple tasks. Imagine watching a philosophy professor agonize over the existential implications of “Hello”—that’s essentially what happens when you ask a reasoning model a simple question.
Generally speaking though, this strategy really worked. And for a few months, this was the new direction. DeepSeek and Qwen quickly followed suit, proving this wasn’t just OpenAI magic but a reproducible innovation. DeepSeek-R1 even pulled back the curtain on this process, showing every token of its thinking—a fascinating if sometimes exhausting glimpse into the AI’s mental gymnastics. OpenAI’s models, by contrast, offer only diplomatic summaries of their deliberations.
For about a few months or so this became the norm, where most leading model providers differentiate between thinking and non-thinking options. This is when Anthropic’s Dario Amodai suggested things can be done differently. He said in an interview the next release of Claude will be a single model (Claude and Opus 4) with variable effort at test time. You can switch thinking (called Extended Thinking in the UI) or non-thinking without switching the models. Programmers using API can also stipulate the amount of “thinking efforts”. Imagine having a single team member who can effortlessly switch between making quick decisions and diving deep into analysis, instead of needing to hire separate people for each task. The key is to guide this versatile employee on which mode to operate in.
Further Reading: Introducing Claude-4
While these thinking models have some baked-in reasoning capabilities, they don’t quite capture how we humans truly understand reasoning. For us, reasoning is a dynamic way of thinking that not only should always be present, but also part of the learning. This is a stark contrast with current LLMs where the ability to reason is always added later, on top of a base model. Secondly, the intensity of reasoning should be adjusted not only by the tasks at hand, but also by the intermediary results: if we are not getting anywhere, we need to think harder. That’s why I refer to the reasoning model approach as half-baked: a fully baked reasoning model takes so much more than token counts.

Mixture of Experts
In the meantime, the transformer architecture evolved. One of the standout innovations that has made its way into the mainstream is the concept of the Mixture of Experts (MoE). While this idea isn’t entirely new—traces of research can be found dating back to 2017—MoE has emerged as probably the single most impactful feature in the evolving LLMscape.
Instead of relying on a single dense feed-forward block typical of the traditional transformer, we now have a multitude of experts along with a smart router or gate that activates only a small subset for each token. Take DeepSeek R1, for instance—a wildly popular state-of-the-art model that boasts an impressive 671 billion total parameters, yet only 37 billion are activated during inference. This clever setup allows us to harness significantly more computational power without needing to use full resources for every single token. While the concept has been applied in some smaller models before (like Mixtral and Grok), the sheer scale and remarkable efficiency ratio (almost 20:1) truly stand out even today.
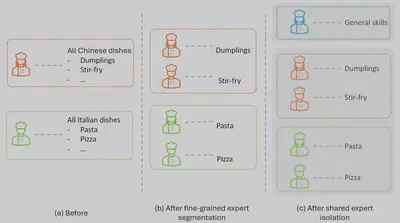
At its core, MoE operates through internal routing at the layer level. It’s not about choosing separate models or reasoning in a traditional sense; rather, it’s about doing less in certain areas so we can achieve more in others. With the model now sparsely activated, the router can iterate for improved results. Plus, having sub-skills (or experts) already separated makes this process even smoother. You can have one expert tackle a specific task while another expert steps in to validate the outcome.
Conceptually, MoE reflects the fascinating idea of activation in our biological brains. While there’s still a lot to uncover about how this process works, it’s clear that our brains are organized into different areas, each specialized for specific tasks, and selective activation is the key to divide the workload effectively. This division of labor is not absolute. Thanks to neuroplasticity, we can reshape certain skills, which is the focus of current research like Mixture of Turnable Experts.
GPT-5 and the Router Mechanism
GPT-5 may be underwhelming for many but it made good steps in simplifying the experience for endusers. Its routing mechanism acts like an intelligent dispatcher, deciding:
- Whether to use a quick, efficient model or engage deep reasoning
- When to call in specialized tools (calculators, search engines)
- How many cycles of thinking to invest
The user interface reflects this with options like “instant,” “thinking,” and “pro”—though behind the scenes, these map to distinct models with different computational appetites. The “auto” setting lets the AI judge for itself, like a smart assistant. The user also has the option to correct this smart assistant by skipping the deliberation and opt for a quick answer.
The problem of router is of course the routing needs to be implemented somewhere outside of the models yet part of the UX. Who is doing the assessment and how is it actually implemented? Here are some ways.
- A tiny classifier (logistic reg., gradient boosting, or a distilled mini-LM) that predicts difficulty/route from the length, language, domain tags (math/code/medical), presence of numbers/symbols, safety/PII flags, or keyword detectors (“prove”, “step-by-step”, “compile”, “error stack”) as weak signals of hardness. This is the most common production choice. Benchmarks like RouterEval/RouterBench are designed for comparing such policies.
- Uncertainty signals from a small/cheap model (entropy of next-token distribution, margin between top-k logprobs, self-consistency across short samples). Strong evidence that uncertainty-driven routing works well if calibrated. This is a bit technical but there are ways we can mathematically determine the uncertainty in the question.
- Conformal prediction–style routers (coverage-guaranteed thresholds on uncertainty). These give you principled “only escalate when needed” rules.
- A judge/critic prompt (ask a small LM to label “easy vs. hard / safe vs. unsafe / code vs. non-code”). Higher latency but simple to stand up.
New Directions: HRM & EBT
If GPT-5’s router represents the present, Hierarchical Reasoning Models (HRM) point toward a radical future. The recent paper HRM (Wang et al., 2025) may become the most important architectural innovation in years.
At its core, HRM is built on nested loops: a slow, high-level planner and a fast, low-level executor, running on different timescales. This structure makes reasoning less brittle than step-by-step Chain-of-Thought, avoids the inefficiency of massive sampling, and internalizes “thinking fast and slow” within the model itself. The result is a tiny, data-efficient system (27M parameters trained on ~1000 samples) that outperforms frontier-scale models on reasoning benchmarks.
While previous models focus on providing scaffolds, adding orchestration external to the transformer models this new idea proposes a new way to think inspired by human brain. Instead of the relentless yet flat token processing pipeline it now weaves hierarchy into the model, giving structure to thinking. This is probably the most important innovation to the transformer architecture since Mixture of Expert. But unlike MoE already implemented in nearly all SOTA models, implementing HRM is much more challenging.
Another promising line of work is the Energy-Based Transformer (EBT). Instead of treating attention as a purely feed-forward computation, EBT re-casts transformer inference as the minimization of an energy function. The model assigns lower energy to “good” reasoning trajectories and higher energy to inconsistent or implausible ones. Generation then becomes a process of iteratively descending an energy landscape, rather than a single left-to-right sweep. You can think of this like a ball rolling downhill until it rests in the lowest valley—that valley represents the most consistent, well-formed solution.
How could this be used? In practice, you don’t throw away your existing transformer. You add a new “layer of judgment” that guides it, nudging the model toward answers that are stable and consistent rather than brittle or one-shot guesses. Over time, this could make models less prone to silly mistakes, because they don’t just blurt something out—they refine it by letting the answer stabilize.
In practice, EBT will probably appear as an add-on to existing transformers, improving reliability on tough reasoning tasks. Eventually, it may merge with some other innovations to improve the internal reasoning capabilities that are lacking in vanilla transformer.
Conclusion
Despite major advances in architectures (dense vs. sparse), scaling laws, and training strategies, reasoning remains an unsolved problem in large language models. Current approaches—whether instruction-tuned models, chain-of-thought prompting, or mixture-of-experts routing—show that today’s systems can simulate reasoning patterns, but they still fall short of robust, generalizable reasoning.
There is a huge space for improvement in several areas:
- Consistency and reliability: Models often reach correct answers but fail in edge cases or when reasoning steps must be precise.
- Transparency: Current reasoning traces (like step-by-step outputs) are surface-level artifacts, not guaranteed to reflect internal processes.
- Generalization: Reasoning strategies that work in narrow benchmarks often collapse in more open-ended, real-world tasks.
- Integration with knowledge and planning: Models still struggle to combine reasoning with long-term memory, external tools, or multi-step planning in stable ways.
In short, while Mixture-of-Experts, instruction tuning, and reasoning-first models (like DeepSeek-R1, OpenAI’s “o” series, or Anthropic’s reasoning-optimized Claude) push the frontier, true machine reasoning is still an open challenge. It will likely require innovations that go beyond scaling—such as new architectures, stronger integration with symbolic or retrieval systems, and deeper alignment between internal computation and explicit reasoning outputs.
A Quick Timeline of Reasoning in LLM
2022–2024 — Prompt-era reasoning: “just ask for it”
- Chain-of-thought prompting and scratchpad-style reasoning emerge in research and practice.
- Demonstrated that simple prompting could improve accuracy on math, logic, and symbolic tasks, but reasoning remained brittle and inconsistent.
Sep 17, 2024 — OpenAI o1-preview released: the power of reasoning revealed
- First widely visible reasoning-optimized model.
- Extended internal deliberation time (“thinking tokens”), showing that giving models more space to reason improves outcomes on challenging benchmarks.
Dec 5, 2024 — o1 released: reasoning made more affordable
- Productionized reasoning: cheaper, faster inference.
- Normalized “reasoning as a product feature” rather than an experimental preview.
Jan 20, 2025 — DeepSeek R1 released: reasoning made explicit and affordable
- Large-scale MoE + MLA backbone, open release.
- Pioneered explicit reasoning traces as a default output, making reasoning not just a capability but a visible part of model interaction.
Mar 2025 — Research on MoTE and semantic specialization
- Studies showed that reasoning in DeepSeek-R1 could be influenced at the expert level (tuning or muting experts).
- Also revealed stronger semantic clustering in expert routing, suggesting emergent specialization of reasoning modules.
May 22, 2025 — Claude Sonnet & Opus 4 released: hybrid models with extended thinking
- Introduced hybrid reasoning strategies: mixing fast dense inference with longer deliberate reasoning passes.
- Expanded the space of “thinking time” allocation, balancing responsiveness and depth.
Aug 7, 2025 — OpenAI GPT-5 released: the new norm of router
- Integrated reasoning and routing seamlessly: router-based mechanisms to allocate “thinking effort” per query.
- Established reasoning as the default expectation in frontier models, not a specialized product line.