The State of TTS: early 2025

This article was originally published at dliangthinks
Generating realistic and believable speech is an immensely important topic in the realm of artificial intelligence applications. The ability to produce human-like speech not only enhances user experience but also opens up a myriad of possibilities across various industries, including entertainment, customer service, and education. In this article, I aim to present some quick test results that illustrate the current state of affairs in this rapidly evolving field.
Recent advancements in natural language processing and machine learning have dramatically enhanced the quality of synthesized speech. Just a few years ago, I found myself relying on professional voice talent for my eLearning projects because the technology was often robotic and challenging to customize for specific pronunciations. Working with voice talents was a joy; their passion for the job was infectious. However, it was also costly and inconvenient whenever I needed to make changes. The pace of technological evolution has been so rapid that I now wonder if any voice talent can still find work in this field.
The implications of these advancements are profound. I predict that AI will replace a third of white-collar jobs within the next decade, and this is an area where that shift has not only begun but also finished. It’s disheartening to witness such changes, especially when you know some of these talented individuals personally and can’t help but think about the new paths they must now explore. Yet, from a societal perspective, the benefits are clear: lower costs and quicker turnaround times mean we can utilize speech technology more freely. What was once a luxury in my elearning projects now feels like a standard expectation.
As AI-generated speech becomes increasingly indistinguishable from human voices, we can anticipate its integration into a wide array of applications. This trend is only set to continue, leading us to a future where AI-generated speech is everywhere. My tests serve as a snapshot of the current landscape, a personal reminder of how far we’ve come.
My tests are conducted using the following text:
The problems plaguing much of eLearning today are numerous. But at its core lies a tendency to imitate traditional textbook-based learning, where, as the name implies, text is dominant and multimedia elements serve merely as illustrations. We may call this the “original sin of elearning”.
OpenAI
As a leading AI solution provider OpenAI currently offer three models for speech generation: TTS-1 and TT1-HD; and a new generation of model called 4O-mini-tts.
TTS-1
Price: $15 million tokens
TTS-1-HD
What does HD mean? According to official documentation, here is how HD differs from regular:
For real-time applications, the standard
tts-1model provides the lowest latency but at a lower quality than thetts-1-hdmodel. Due to the way the audio is generated,tts-1is likely to generate content that has more static in certain situations thantts-1-hd. In some cases, the audio may not have noticeable differences depending on your listening device and the individual person.
4O-mini-tts
Compared to OpenAI’s previous generation of models, it has more steerability, namely, vibes, tones, and effects. I described this in more detail in the test concerning Chinese. The quality of the sound is definitely better, yet compared to TTS-1-HD the speech is not always substantially better. However, the price is significantly more affordable.
Price: $0.6/million tokens, or 1.5 cent per minute
Elevenlabs
ElevenLabs is a key player in the industry, offering a diverse family of models to suit various needs.
- Flash: This model focuses on low latency, clocking in at around 75 milliseconds, making it perfect for real-time interactions.
- Turbo: While it offers slightly higher latency at about 250 to 300 milliseconds, it delivers enhanced quality, striking a good balance for conversational AI.
- Multilingual v2: This flagship model has more lifelike output, although it doesn’t specify latency, making it ideal for applications like e-learning where real-time response isn’t as critical.
In summary, the first two models are tailored for scenarios where quick responses are essential, while the Multilingual v2 shines in non-real-time settings.
Here is the flash version:
And here is the multilingual version:
Cartesia
The company is focusing on the domain of realtime speech where its latency is the king. Sonic is the standard model and current in v2.
Voice: Sophie
Wellsaid
Wellsaid may not be as widely recognized as some of its competitors, but it has been my trusty workhorse for numerous projects in the past. I simply can’t leave it out of this comparison! The clarity of its voice is truly outstanding.
Selena: I’ve relied on this voice for many of my projects, and it never disappoints!
Minimax
Minimax is a newcomer to the scene and has achieved impressive results in the AA leaderboard.
Kokoro
Open source, lightweight, and incredibly fast—what’s not to love? You can get started for just $0.80 per million tokens at deepinfra.
Plus, if you prefer, you can host it locally, as long as your language fits within its capabilities.
Voice: heart (this is the best model; BTW kokoro means heart in Japanese)
Voice: Bella (the voice has some rough edges and are not suitable for commercial purposes)
Sesame
Sesame isn’t in the business of competing with TTS through API. In a recent interview, the CEO shared that the company is focused on a product I previously discussed in another article titled “AI Companion as Interface to Computing.” What’s currently available to the public is actually a scaled-down version of Sesame’s full capabilities, known as Sesame CSM 1B. You can check out a demo hosted by Hugging Face here.
I’ve explored some of the voices available, and let me tell you, they’re a mixed bag! Here’s what I found:
- conversation_a: Not very useful, with a British accent that doesn’t quite hit the mark.
- read_speech_a: An okay female voice.
- read_speech_b: A good male voice that’s definitely usable.
- read_speech_c: Another British male voice.
- read_speech_d: A lazy female voice that I wouldn’t recommend.
Overall, for someone who has experienced the magic of Maya, this is deeply disappointing!
Dia TTS
Dia from Narilabs was a promising product if you look at their samples. They have ambitious plans to create something akin to Sesame, which is what people wanted to hear.
However, the model currently generates audio of a fixed duration (30 seconds?). This means that when longer texts are processed, they end up getting compressed, resulting in a rather chipmunk-like sound. Take a listen to this podcast created with Dia to hear the outcome!
How About Chinese?
How well do these TTS systems handle Chinese, or any language beyond English? This is a crucial question, as many TTS engines often stumble over the subtleties of non-English languages due to inadequate training. I’m particularly interested in Chinese, my native tongue, where I can easily detect even the tiniest issues with intonation. Sadly, this challenge isn’t limited to Chinese; it also affects several other Asian languages that frequently get overlooked.
My tests are conducted using the following text, from the first line of The Pursuit of Nothingness:
在我所余的生命中可能再也碰不见那两个孩子了。我想那两个孩子肯定不会想到,永远不会想到,在他们偶然的一次玩耍之后,他们正被一个人写进一本书中,他们正在成为一本书的开端。
When it comes to Chinese TTS, for a long time Microsoft Azure’s voices are the only ones that are acceptable to me. Here are some examples:
Yunjian:
Yunxi:
However, like many of its products have demonstrated, Microsoft just doesn’t understand what is a good user experience and has made it incredibly hard to use their service. I still recommend this product because there currently exists a free way to use the API.
OpenAI TTS-1 (not really usable)
openai.fm (they are using 4o-mini-tts with instruction). Obviously the new tts model is of a higher quality.
My own api call using 4o-mini-tts with instruction “sincere”. This voice sounds like someone who learned to speak Mandarin from outside of mainland China or Taiwan.
Here is how to structure the api call according to openai.fm github page:
try {
const apiResponse = await fetch("https://api.openai.com/v1/audio/speech", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "gpt-4o-mini-tts",
input,
response_format,
voice,
// Don't pass if empty
...(prompt && { instructions: prompt }),
}),
});
As you can see, the new tts model received a json file for what needs to be generated:
{
"model": "gpt-4o-mini-tts",
"input": "This is the actual text I want you to read aloud.",
"voice": "nova",
"response_format": "mp3",
"instructions": "Voice Affect: Calm, composed, and reassuring... Pauses: Before and after the apology..."
}
I’m using Nova with the following voicing instructions:
Voice Affect: Calm, composed, and reassuring. Competent and in control, instilling trust.
Tone: Sincere, empathetic, with genuine concern for the customer and understanding of the situation.
Pacing: Slower during the apology to allow for clarity and processing. Faster when offering solutions to signal action and resolution.
Emotions: Calm reassurance, empathy, and gratitude.
Pronunciation: Clear, precise: Ensures clarity, especially with key details. Focus on key words like "refund" and "patience."
Pauses: Before and after the apology to give space for processing the apology.
OpenAI operates on a token-based pricing model, which means that the text you enter in the instructions field can use up additional tokens, potentially affecting your overall costs. The official rate is $12 for every 1 million input characters. So, if you’re sending small snippets of text that are similar to or even shorter than the voice instructions, you might discover that a significant portion of your costs comes from those instructions!
Cartesia Voice: Chinese Reading Woman (there is a little problem but overall very good)
Minimax
Voice: news anchor woman (extremely impressive)
In conclusion, both Cartesia and Minimax are usable. But I keep Microsoft as an option because of the cost.
Summary
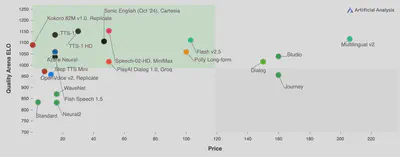
Artificial Analysis runs a speech arena where users are invited to evaluate models. This is the result circa end of April 2025.
Check out the newest result here.

For commercial applications that are latency sensitive, here is a site that does some of the comparison work.
https://app.coval.dev/tts-benchmarks
In conclusion, here are my thoughts:
- It seems that the current generation of speech generation technology has reached a plateau, meaning we might not see substantial advancements in this area for a while.
- However, real-world applications often require lower latency or reduced costs, which could spark the development of specialized models tailored to these needs.
- Open-source models are proving to be competitive with mainstream state-of-the-art models. They would be a good choice if you have the resources to host and run them effectively.
- When it comes to conversational speech, the complexity far exceeds that of text-to-speech. There are still numerous challenges to tackle, and some issues remain so elusive that we haven’t even named them yet! While Sesame is at the forefront of research in this domain, its closed-off approach is unfortunately slowing progress.