From Turks to HAL: the eccentric journey of voice machines
 How would our contemporaries react to talking heads? Smashing is no longer an option.
How would our contemporaries react to talking heads? Smashing is no longer an option.La voix annonce un être sensible; il n’y a que des corps animés qui chantent. Ce n’est pas le flûteur automate qui joue de la flûte, c’est le mécanicien, qui mesura le vent et fit mouvoir les doigts.1
—Jean-Jacques Rousseau2
According to Plutarch3, a man plucked a nightingale and finding almost no meat, said, “Vox et praeterea nihil.”4 Given the context in which this passage is found, and the fact that all other passages around it explicitly indicate that Spartans are the bearers of action, it is rather curious that in this case Plutarch doesn’t specify this man as a Spartan. Perhaps here Plutarch felt that although the Spartans have good reasons to despise the “art of speaking”, they are going too far by being overtly gluttonous5; more importantly the man fails to recognize the value of something that Kempelen, Wheatstone and Bell will surely appreciate — and I hope the reader of this essay will do the same – namely, what a well made voice machine a nightingale is!

On this note it may sounds less blasphemous if I were to state that a Diva can be regarded as a machine perfected in voice production. To many a profound humanism seems to take residence in the body of a diva—which effectively hides its workings—and to exude from there a divine radiance which defies scrutiny. One can indeed indulge in the question that what kind of reveries a voice is capable of evoking, but there is certainly an engineer’s view, as in every other case. Vocal method, sometimes referred to as the art of singing, always has a scientific side. Even a casual look at the Bel Canto tradition will reveal that what lies beneath the art are immensely corporeal techniques and onerous trainings that benefit from a progressive and scientific knowledge of the human body as a voice producing machine. In numerous books that bear the title of vocal pedagogy, pages and pages of technical details read not unlike they are excerpted from the operating manual of an intricate and delicate machine6.
This engineer’s view of the human body is hardly anything new. Imagine what the 18th century materialist Julien Offray de La Mettrie would say upon examining the nightingale: “a perfect voice machine and nothing else”. And here nothing else is in fact a virtue that signifies the ultimate economy of the system, with absolutely no unnecessary parts.


La Mettrie’s position was historically taken as a rejection to the Cartesian dualism of mind and body. He claims in L’Homme machine that “since all the faculties of the soul depend to such a degree on the proper organization of the brain and of the whole body, that apparently they are but this organization itself, the soul is clearly an enlightened machine”7Not only does he eliminate the raison d’être of soul, but between man and animal, he sees only differences in degree.8And what remains to be done — the logical extension of the argument—is to reproduce the living organization through whatever technical means that are currently available. In the 19th century, the cog, piston; in the 21st century, computer code and electronic chips.
The soul is not the topic of this paper. Instead what I can deal with is a more tangible yet still intangible matter, that is, the voice. To make this intangible matter tangible, I present a history of voice machines, or should I call it a technological history of voice. What I mean by voice machine is, naturally, machines that produce voice. But somehow this always seems to mean voices produced by machine, or even better, to conceive voice as something that is not produced yet, that resides temporarily in its pristine form. But as we speak, the voice emerges. And a particular kind of voice, I might add. A history of how the technology of voice production evolves, therefore, is also about the coming into being of this nonhuman, imitated voice. This other voice.
Act I: A history of this other voice
Why this history matters? Perhaps it suffices to say that it is invariably the encountering with the other that forces us to know ourselves better. The history of voice machine brings new meaning to our understanding of the voice in two ways: first, it considers voice (and implied in the argument many other anthropomorphic qualities) as the feature of a technological mechanism. This technological view of human can be traced back to Aristotle and has become a prominent position in philosophy (thanks to La Mettrie) since the seventeenth century. Second, this notion highlights the perception of such a technology: it is never quite a matter-of-fact demonstration of a scientific principle. Popular imagination is quick to be ignited by the uncanniness of such a view that it has become a persistent theme in 19th century literature from E. T. A. Hoffman to Villier de L’Isle Adam.

Our speaking machine was naturally more humble in its capacity. The few phrases it was capable to articulate was not enough to enrapture the soul, as Olympia or Hadaly were made for. But it is no more humble than our current technology compared with what the machine is capable of in the Terminator series. The fact is: voice machine was mixed with automaton (a more up to date terminology says: robot) from the beginning. It is for this reason that I want to start this history of voice machine with Wolfgang von Kempelen, not because I believe such history has a point of departure, as it often seems in its literature. What precedes Kempelen remains at this time in obscurity – there is a huge gap between the Greek talking gods (priests speaking from a pipe that leads to stone statues and making prophesies) and this Hungarian in the service of Austrian court, who, instead of constructing a myth, constructs a machine, which is built upon years of patient research (twice he had to start from scratch), whose result can be documented (in the form of a treatise), reiterated (by Wheatstone and Bell) and most important of all, improved upon. But if I venture to say that Kempelen represents the evolutionary progress of technology and the scientific spirit, I run the risk of ignoring what made Kempelen most famous and a central figure in another history, that is, the history of priest, magician, spirit medium and all other kinds of showman, for Kempelen is mostly remembered for his “automaton”, the Turk, a Turkish chess playing puppet that enjoyed great notoriety during his lifetime. After Kempenlen’s death in 1804, the Turk was acquired by one Johann Nepomuk Maelzel, who matches Kempelen in both engineering ingenuity and showmanship. His American tours form the basis of Edgar Allan Poe’s “Maelzel’s Chess-Player”, hailed as a predecessor of his famous detective novels.

From today’s hindsight, that is, our understanding of the limits of eighteenth century technology, and with the achievement of Deep Blue fresh in our mind, it would be easy enough to surmise that this had to be a hoax. Although a handful of persons had voiced a similar doubt at the time, their determination to expose the mechanism of the Turk never really compromised its immense popularity. Naturally, in an “age of the automaton” where mechanical construction represents a state-of-art technological achievement that offers infinite possibilities to the imagination — at least in the early days of the Turk’s lifespan – to see the limits of that particular technology is literally beyond one’s horizon. And remember that this was the time when the industrial revolution had not led to various dystopian concerns which now permeate every inch of our perception of technology. Those who arrived at the right conclusion that there must be a human speaking from the Turk relied on the incorrect assumption that a mental operation such as playing chess cannot be accomplished by a machine.

Kempelen, a man of linguistic, administrative and engineering talents started his speech machine after the Turk. It is interesting to observe that in building something like the Turk, he effectively traced the steps of the ancient talking gods, where a human being hides behind the façade of what appears to be inhuman. And therein lies its power to inspire — the capacity itself, be it speaking or playing chess, is trivial; what impresses is the fact that this capacity is now disassociated with human. After his patron Maria Teresa’s death in 1780, Kempelen was to tour Europe against his own will with the Turk. At this time the speech machine was already half-finished and sometimes exhibited together. Mladen Dolar describes9 a fascinating double bill attraction which consists of a back-to-back show of the chess automaton and the speech machine. According to this account, Kempelen came up with an ingenious way of compositing his show: not only did he let the speech machine introduce the chess automaton, but he constructed the former so as to exhibit maximum mechanicity whereas the latter took up the appearance of a human being — the dress, the rolling eyes, the name “Turk”. This arrangement is effective because once the former’s mechanically constructed nature (which is in bare view) is established, the next subject it introduces is less likely to engender any suspicion that it might be of a different nature. The two work hand in hand, as if they form a device of double functions - speaking and thinking- that only humans are capable of; it also seems to demonstrate the critical link that leads speaking to thinking10. Kempelen continued to improve his design until in 1791 when he published a book detailing his method, under the title “The mechanism of the human speech with the description of a speaking machine”.
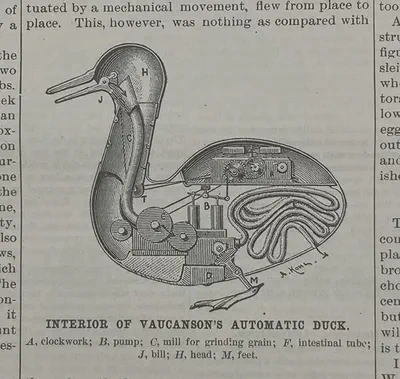
Kempelen’s speaking machine, however, needs not start from scratch. Vaucanson had already built something before him. The core of Vaucanson’s machine consists of an artificial lung driven by bellows, a windpipe through which the air pressure can be mediated, and lips which acts like a valve. In short, it is a mechanical model of the human respiration system, which is then integrated into the form of a flute player, whose fingers are programmed to move the flute accordingly. This machine, however, is not designed for and is not yet capable of speech production. Vaucanson bypasses the problems of speech construction by simplifying the model to a great extent (imagine a mouth without the tongue!). His ingenuity also lies in finding a task that is to be associated with the human only – where it acquires its sensational value-yet is sufficiently feasible from the engineering perspective. The flute player was an instant success.11 All of sudden, it seems the task of building a speaking machine is no longer a dream. La Mettrie refers to this prospect as,
…and Vaucanson, who needed more skill for making his flute player than for making his duck, would have needed still more to make a talking man, a mechanism no longer to be regarded as impossible, especially in the hands of another Prometheus.12
This is exactly what Kempelen did. Building on Vaucanson’s model, Kempelen refined the speech organ and it took him almost twenty years to perfect it (his famous Turk, on the other hand, took six months). His device consists of two joined oval boxes which are able to produce vowels. To this he added a glottis that enables the consonants PMNL. Sets of levels controlled additional S, Sh, Z and R sounds. Kempelen’s machine even features a pitch control that adds intonation to the words and short sentences it is capable of speaking13.

Around approximately the same time, another speaking machine was probably made by an Englishman, Erasmus Darwin, the grandfather of Charles Darwin. Unfortunately the only evidence available of his machine is a brief passage in his magnum opus.
I have treated with greater confidence on the formation of articulate sounds, as I many years ago gave considerable attention to this subject for the purpose of improving shorthand; at that time I contrived a wooden mouth with lips of soft leather, and with a vale back part of it for nostrils, both of which could be quickly opened or closed by the pressure of the fingers, the vocality was given by a silk ribbon about an inch long and a quarter of an inch wide stretched between two bits of smooth wood a little hollowed; so that when a gentle current of air from bellows was blown on the edge of the ribbon, it gave an agreeable tone, as it vibrated between the wooden sides, much like a human voice. This head pronounced the p, b, m, and the vowel a, with so great nicety as to deceive all who heard it unseen, when it pronounced the words mama, papa, map, pam; and had a most plaintive tone, when the lips were gradually closed. My other occupations prevented me from proceeding in the further construction of this machine; which might have required but 13 movements, as shown in the above analysis, unless some variety of musical note was to be added to the vocality produced in the larynx; all of which movements might communicate with the keys of a harpsichord or forte piano, and perform the song as well as the accompaniment; or which if built in a gigantic form, might speak so loud as to command an army or instruct a crowd.14
From this description we may infer that Darwin indeed built a speech machine, otherwise he wouldn’t have known that it produced an “agreeable tone”. It also seems that his model had been exposed to a selective audience. But apparently this exposure is far from extensive enough to enable a fellow countryman such as Charles Wheatstone to gain any knowledge of it. Indeed Wheatstone relied upon the documentation provided by Kempelen to build his own copy of the voice machine. Naturally, both devices are to be operated in a similar manner.
“The right arm rested on the main bellows and expelled air though a vibrating reed to produce voiced sounds. The fingers of the right hand controlled the air passages for the fricatives /sh/ and /s/, as well as the ’nostril’ openings and the reed on-off control. For vowel sounds, all the passages were closed and the reed turned on. Control of vowel resonances was effected with the left hand by suitably deforming the leather resonator at the front of the device. Unvoiced sounds were produced with the reed off, and by a turbulent flow through a suitable passage.”15
Wheatstone’s machine served no better purpose in our history than to impress the little Alexander Graham Bell, to whose father he was befriended. Bell saw Wheatstone’s demonstration of the machine and, when Wheatstone loaned the Kempelen book to them, “devoured” it (it was a French version). He then set out to build one, encouraged by his father and assisted by his brother Melville. The boys start by making a cast from a human skull and molding the vocal parts in gutta percha. The lips were a framework of wire, covered with rubber stuffed with cotton batting. Rubber cheek provided complete enclosure of the mouth cavity. The tongue was designed as wooden sections operated by levers, like the dampers of a piano. As for the larynx, his brother’s division of labor, it was constructed of tin and had a flexible tube for a windpipe. Finally, the vocal-cord was implemented using two slotted rubber sheets the edges of which touched one another. This rudimentary voice machine, in its first test-run without the tongue (because the boys can’t wait), showed great potential. Without being able to utter yet any real speech, it already had a voice—“it no longer resembled a reed musical instrument, but a human voice.”16 The simple combination of opening and closing the rubber lips with blowing through the windpipe produces ma-ma-ma “quite clearly and distinctly”17. They even manage easily to pronounce it in the British fashion. The ensuing passage, probably the liveliest one in this entire recollection, tells us how the boys were able to deceive a lady upstairs into believing that she actually heard a baby “in great distress calling for its mother.”

It now seems clear that the question lies not in how vocal sounds can be produced, but rather, how can they be produced in rapid succession, and thus to form phrases and even sentences. To achieve this purpose, it is almost inevitable that the human-machine interface has to be standardized. Petals and keyboards naturally come to mind. Joseph Faber adopts precisely such a solution. His Euphonia features a female head (was it to remind its audience of the power of Medusa?) connected from the rear to a huge bellows; these two then hang above what seems to be a piano, whereby an operator presses keys/levers (there are seventeen of them) to produce sentences. Joseph Henry (who later encouraged Bell in his work on the telephone) came across Farber’s “Wonderful Talking Machine” while it toured Philadelphia. Having seen Wheatstone’s machine earlier, he commented that Farber’s machine is far superior (in that it speaks English better than its German inventor).
Farber’s invention, marvelous as it was, received little public attention or financial support. Perhaps the heyday of the voice machine (at least the mechanical version) is over? One last attempt along this line of thinking was Richard Riesz’s mechanical talker in 1937. Riesz made the vocal tract shaped more like the one found in humans. The control mechanism borrows from another musical instrument: the trumpet (was it from Maelzel?). With ten control keys (or valves) operated simultaneously with two hands, the device could produce relatively articulate speech with a trained operator. Reports from that time stated that its most articulate speech was produced as it said the word “cigarette”.18


Riesz’s project is later integrated by Homer Dudley, a fellow Bell Telephone Labs engineer who invented VOCODER(voice encoder), into a much updated version of a voice machine. It is exhibited by Bell Telephone at the 1939 World’s Fair in New York and San Francisco. This machine, known as the Voder (Voice Operation DEmonstratoR), is operated by a young woman, who is specially trained to manipulate the rather complex system of keys, knobs and foot-pedals in order to produce a voice.
Act II: the eviction of human
While the early models of voice machines invariably took the form of mechanical devices, modern voice machines usually develop in electrical terms. This change can be viewed as a positive one, as signaling our better understanding of human faculties. Flanagan put it bluntly, “Much treachery lies in trying to model nature verbatim, rather than in terms of underlying physical principles.”19 But the development of our understanding of these underlying principles is simultaneously a process in which human form is evicted from the machine, a turning away from the visual mimetic form, which is increasingly understood as contingent. Voder exemplifies this Satyric half mechanical, half electrical monster; it gives us a last glimpse of a monster that still retains a recognizable and associable form (a musical instrument), and even more importantly, like all his uncanny siblings and ancestors, ultimately it requires the human hands for its operation. Modern speech synthesizers, however, function completely independent of human intervention. Paradoxically then, when an “scientific” understanding of human speech is finally achieved, human is no longer needed - these new speech machines are truly automatons and they are everywhere. Perhaps, as Lisa Gitelman put it, “The very idea of a ‘Talking Machine’ seemed impossible, the term an oxymoron. It denoted a contradictory combination of biological and mechanical function, a nineteenth-century cyborg.”20
Curiously enough, the human returns in another form. In GPS, telephone answering systems and many other speech synthesis applications, a TTS (Text to Speech) engine and recorded human voice are often used in tandem. This creates an auditory scenario that might, I imagine, perplex the uninitiated, for instance, an imaginary visitor from the earlier centuries, to whom the voice still possesses a strong indexicality to the human. Much like photography, whose indexicality to reality has undergone a century long process of deteriorating, what quantity of human value does a voice still possess, if any at all? Will we eventually arrive at a point where, “Nothing human is natural; that which is natural about us is inhuman”?21
We have had enough of hindsight. What would it be like when the ideal technology of speech synthesis has been achieved, deployed and has become our everyday reality? Perhaps someone has already answered the question. In Stanley Kubrick’s 2001: A Space Odyssey, a supercomputer anthropomorphized as HAL is “equipped” with both an eye22 and a voice. But the way in which his (assumed here by the male voice) vision and his voice is depicted bears interesting differences that deserve further elaboration. First, although he does see with his eye — and lip reading for that matter — the way in which this eye is implemented bears little resemblance to its human equivalent. It is basically in the shape of a surveillance camera embedded in the various control panels with immovable fixtures – we have plenty of close-ups of it engaged in the intensive act of seeing; yet in all these shots it does not blink, tilt, or zoom. But HAL’s voice is nothing of the sort. Not only does it bear immense resemblance to a human voice in its hypnotic quality, it is often perceived as having more human qualities than a real human. According to Sobchack,

HAL’s voice is ripe and soft whereas Bowman’s and Poole’s have no texture. In comparison to the astronauts, creating the context which emphasizes the lackluster and mechanical quality of human speech spoken by humans, HAL-in the first part of the flight-can almost be regarded as a chatterbox, a gossip, emotional.23
In the second part of the flight the voice only gets even more human: it withholds information, tells lies, refuses to respond and dismisses the conversation in an advantageous position; when it senses a disadvantage it bluffs, begs, and finally, giving up all hope, it sings like a drunkard, “Daisy, Daisy, give me your answer, do. I am half crazy all for the love of you…” In a tour de force passage of Bowman’s dismantling HAL, where the change of this voice builds arguably the most sentimental moment in this utterly nonchalant film, Kubrick’s mise-en-scène of the voice effectively contrasts the whole range of vocal expression with the single most non-expressive one conceivable: the sound of rhythmic breathing. As one critic observes,
The scene induces deep discomfort among many who watch and listen to it. Indeed, it is the only one in the film to engage one’s sympathies on behalf of a character. And the fact that the character consists of a bug-eyed lens, a few slabs of glass, and a disassociated voice is the best possible tribute to Kubrick’s success in creating a mechanical artifact more ‘human’ than the humans.24
Under no circumstance are we presented a visual source of HAL’s voice. We always hear this voice together with the image of its monocular eye. Although I suspect the metal mesh immediately below the eye-camera could be the speaker, the intimate texture of the voice – it doesn’t have a room tone like the other characters’ voices; it doesn’t have a resonance–makes us feel the voice is sounding inside our brain. In other words, not only the voice is disembodied, it takes our body as its own, potentially. Equally important and in support of this view is its omnipresence. It follows you to anywhere inside the spacecraft.
Dolar’s anecdote25 of an Italian captain’s bravura calling upon his soldiers to attack resonates in this context. The soldiers’ response, instead of marching forward, is “che bella voce!” And somehow this is exactly what I felt when I first heard HAL’s voice. This beautiful and docile, assuring yet assured voice, isn’t it the ideal voice that keeps a man company in his most desolate times (of which space travel is naturally one)? HAL is a voice; and it is much more. It executes your commands and carries out routine tasks through the interface of voice. It is probably not a coincidence that in virtually all Hollywood depictions of the future, voice plays a critical part – all commands are delivered through voice and answered by voice – voice is our interface to technology; the interface to the future. This is HAL’s legacy.
Nothing HAL says is, in itself, remarkable. What is remarkable is that he says it. Here we reiterate the secret of all voice machines through the ages. The banality of language is contrasted with an emotionally charged voice, and together with it, a sort of aspiration we perceive from it, as Sobchack analyses:
That human voice talking about feeling, its almost mystic presence unseen but heard, buried somewhere in the solid state memory units, contained, trapped-that voice and emotion move us. For a machine aspiring to or achieving humanity strikes us as incredibly poignant-a feeling generated, of course, by our own insular and limited moral and emotional imagination.26
Ultimately, it is not even the voice that matters; it is our perception of it in the context we find it. HAL’s voice, in itself, does not have the quality Sobchack describes. It is just an actor (Douglas Rain) and human. Ironically however, Rain’s voice is not manipulated when the machine still functions as a machine. It is only when this voice needs to show a genuinely human quality (e.g., being nostalgic about one’s childhood) that it is heavily manipulated by a vocoder. The resulting Daisy song, with its heavy lower bass, sounds almost like the growling of a giant beast. The idyllic content of the song and the monstrous voice is a second level of contrast that is built into Kubrick’s mise-en-scène.
Intermezzo: making voice visible
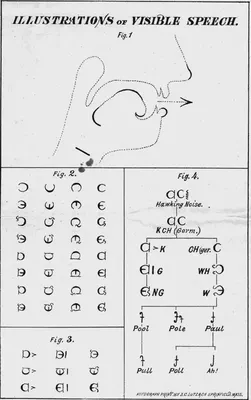
In tracing the history of the speech machine I have largely avoided engaging with a peculiar branch of the research. This is the speaking aid machine that is designed to help with amyotrophic lateral sclerosis, autism, stroke/aphasia, cerebral palsy, developmental delay and other kinds of speech disabilities. In fact, speech disability bears a prominent relation to the technology of voice, and Alexander Graham Bell’s childhood is perhaps the most colorful and illustrative such story. His grandfather (Alexander Bell of London) was an elocutionist and corrector of defective utterance, who initiated this family interest in studying speech mechanisms. Bell’s father, Alexander Melville Bell, devised a universal alphabet for recording the sounds of all languages. Every symbol in this system denotes a particular action/position of the vocal organ so that any sound emitted can be faithfully reproduced later. Bell, in his very lively account, told us how when he was a boy he helped with the demonstration of this system. Volunteers were called to utter “the most weird and uncanny noises, while my father studies their mouths and attempted to express in symbols the actions of the vocal organs he had observed.” The boy was then called in (he was sent out first) to reproduce the sound according to the symbols. And the audience “at once responded with loud applause.” Another example Bell recounted is that he was able to pronounce the “cerebral T” in Sanskrit to the great satisfaction of a professor of Hindustani “without even having heard the sound at all.”27
Melville Bell’s phonetic system represents a giant step in the evolution of physiological phonetics. He was preceded by Baron Franciscus Mercurius ab Helmont (whom Kempelen quoted) and Bishop John Wilkins, both in the seventeenth century. Melville published his study as Visible Speech-The Science of Universal Alphabetics in 1867. His classification of speech sounds became the basis of Sir James Murray’s method of noting pronunciation in the Oxford Dictionary28. What the system is capable of producing is a superset of human speech – it includes whispers, whistles, sobs, grunts, clicks, hisses, signs, coughs, sneezes, kisses and all other sounds producible by the human vocal mechanism. Graham Bell himself later explained the system in his own Mechanism of Speech, and the universal alphabet in it covers “84 consonants and vowels, many not to be found in any language.”29 If this is true, then what we are dealing with here is no longer phonetics (a system bounded by linguistic facts), but a case of representing voice (a system bounded by human voice potentialities). Moreover, what matters now is not to make the voice audible, but visible. In fact, what Bell envisions as the function of his speech machine is not to reproduce speech, but rather, to visualize it. In Bell’s own words, it is “developing an apparatus that would enable my deaf pupils to see and recognize the forms of vibration characteristic of the various elements of speech.”30 This “vibration characteristic”, which later takes the form of a membrane, is what made the first telephones possible.
Melville’s system resembles a prototypical TTS system in that it consists of a database of entirely discrete sounds plus specific rules on how to pronounce them together. This system solves the problem of recording by notating human utterance by an alphabet, but still relies on an organic sound reproducer that is the human. Similar to a Voder operator, the sound reproducer has to associate a myriad of sounds with their visual representation, as well as applying on the fly a complex set of pronunciation rules. This task is a daunting one, one that these days we always reserve for computers. The alphabet itself, moreover, is not exactly efficient for what it is designed to do- simply pronouncing the letter M, for example, requires four symbols and these four symbols are further combined into a single character31. For these reasons, Melville’s system proved to be yet another admirable intellectual exercise that has little practical value.
Committed to the same task, Bell directs his own research into another direction: the spectrograph. This approach introduces the machine into voice recording and reproduction. The machine transcribes the sound into visible spectrums that later can be reliably and efficiently reproduced by another or the same machine. Towards the end of 19th century, Bell’s Volta laboratory conducted numerous studies visualizing sound in the form of spectrum. In 1947 Ralph Kimball Potter made probably the last effort to use spectrogram, as a system of symbols, to designate speech. Nevertheless the symbols lack in definiteness and uniformity so that they can hardly be classified as alphabetic in the stage of development described. The idea of associating a writing system with the human voice is an ancient one and has its own genealogy that cannot be fully explored here. What remains relevant, however, is a similar shift from human agency to machine, to the automation of task.
Act III: mechanicity, vocality, musicality
Perhaps it is high time to discuss a little the difference between speech, voice and human utterance, since I may give the impression that I use them indiscriminately. According to Merriam Webster, a voice is above all a “sound produced by vertebrates by means of lungs, larynx, or syrinx; especially sound so produced by human beings.” The Oxford English dictionary has it as “the sound produced in a person’s larynx and uttered through the mouth, as speech or song.”
Speech, however, is simply defined as the result of the act of speaking, which may or may not take the form of language; utterance, again, is the result of the act of uttering, whose meaning comes from outrer, go beyond. Compared to speech and utterance, voice is the only word that is not defined by an act, but by a mechanism, a property of the organism, that is, a potential form of action (I very much like to analogize it to Bergson’s notion of durée). It is also the only word that incorporates all three branches of meaning: mechanicity, the fact that a voice is produced by physical entities that are sometimes hidden from view but are never invisible – a voice is always produced but a soul is not; vocality, the particular quality of utterance that varies from human to human; musicality, the possibility of regarding the voice as a range of pitch or type of tone side by side with musical instruments.
According to these distinctions, a ventriloquist produces speech with a modified set of organs. This voice differs from an ordinary voice in that its mechanicity is hidden and not corroborated by the movement of lips. The opposite of this is the open mechanicity of operatic singing, where the organs of voice production—and many would agree that this type of voice mobilizes far more organs than is normally required - are explicitly at work. Following this logic, when mechanical talking devices were rapidly replaced by electronic speech simulators (known as speech synthesizers), models of the human vocal tract could now be created in the form of electrical circuits, whose functioning becomes invisible since it does not have any moving parts. The creation of dedicated hardware speech synthesizers, therefore, signifies the furthest internalization of voice in its history.
The young Alexander Graham Bell once produced Sanskrit speech without knowing it. Similarly, when a machine speaks, it does not know what it is speaking apart from the set of rules it is programmed to follow. What I aim to postulate from this parallel is this: a machine may not know what it is speaking – therefore it does not have speech-but it does have a voice. The machine does have a voice of its own.
To conceive a voice machine as a musical instrument, as we have seen, is not only a natural solution to the problem of controlling its movement with better efficiency; it is also an implication of the musicality of voice machine. Darwin’s conception of the voice machine, for all its lack of further evidence, is curiously explicit about this. For Darwin the musicality of the human voice seems a paramount criterion that he may well believe the task of such a voice is to produce “plaintive” singing. What led him to this analogy to musical instruments may well be an active pursuit of musicality in human voice reproduction. Helmholtz did the same thing. According to Bell, he “had not only analyzed vowel sounds into their constituent musical elements, but has actually produced vowel sounds by a synthetical process, by combining musical tones of the required pitches and relative intensities.”32
The word vocality also has a certain connotation with regards to music. Generally speaking, it refers to the kind of utterance that is largely non-verbal, or excessive for verbal communication. The material quality of the voice, however, need not be severed completely from the domain of language, where it can be distinguished in by accent and intonation. Intonation is linguistically describable and constitutes a touchstone of the authenticity of oral speech. Accent is less so, but insofar as it is defined by a regional norm, it lends itself to phonemic analysis and comparison. But where is the individuality of the voice, one that identifies the voice of a certain person? Is there something that is neither accent nor intonation? What tells apart two speakers of one and the same dialect, delivering one and the same message? There are also cases where one’s accent is hard to be identified as belonging to a distinct dialect. In this case, would one apply a multiple of dialects upon a single individuality of voice or should we abolish instead the notion of accent in favor of a broader category of which accent is merely a subcategory?
In the sense that voice operates on a certain frequency range (pitch) and has a certain timber, it is a particular kind of musical instrument. But it is also a privileged musical instrument because it embodies, beyond the musical meaning, a layer of semantic meaning. Timbre is a concrete referentiality. The recognition of a certain timber refers to a concrete object/phenomenon in this world. Semantic meaning, on the other hand refers to an arbitrarily defined syllable that does not correspond to anything concrete, but only acquires meaning in a system of differences (recall Saussure’s famous phrase “in language there is nothing but difference”). Interestingly, these two layers often compete for our attention. We are accustomed, in everyday life, to extracting semantic meanings while ignoring the musical aspect of the voice. In our daily overexposure to voice, we rely on the routine of decoding linguistic information from these sounds, to the extent that these sounds have become for us nothing but the carriers of semantic meanings. On the other hand, we are often baffled in encountering a foreign language that we do not speak, or in trying desperately to make sense of an infant’s pre-linguistic babbling, because all of sudden the voice loses (or has not yet gained) its signifying layer. But it is also at these moments that we are once again confronted with the sounds of speech-voice turns to music anew33.
This is where Sonovox, a particular kind of voice machine, comes into play. A Sonovox uses basically the human vocal tract (throat) as a filter for the output of a musical instrument. It modulates the musical instruments so that they too can speak, that is, have a semantic layer. Naturally, what really speaks is the human performer. And what the machine does is to connect the human with the musical instrument in an alternative way. Instead of a human playing the musical instrument – you can utter human speech through the musical instrument—now the musical instrument speaks through the human. This unexpected reversal not only exposes the material base of human articulation but also produces a musical voice which became highly desirable since its inception in the 1940s.34
Act IV: representing voice
In its natural state, a voice is spoken, heard and perceived as belonging to an individual. In the case of a voice machine, however, we might say the voice is represented. The recording and the transmitting of human voice are perhaps two of the most far reaching inventions of the last century. The emergence of these two technologies, or rather, clusters of technologies, can be regarded as the progenitors to the speech automata tradition that we described. Epistemologically speaking, however, these devices offer a new form of representing the voice.
In hindsight, we often say, in terms of reproducing any human sensorial faculty, there are always two discernible options. The first consists of reproducing it as it is produced by its native organ. The science of modeling after nature, now officially baptized as bionics, can be traced back at least to the legend of Icarus, whose father held this naïve belief that all that it takes is a pair of wings to fly like birds. Da Vinci seemed to have learnt the lesson—he designed his flying machine (or rather glider) still after birds-by conceiving a better way to glue the wings to the body (belts strapped to the legs and body of the flier). The second way is to understand what is exactly produced by a human and then implement it in other terms.
In the field of speech reproduction, the same thing happened. Contrasting the first approach (of which Faber’s Euphonia is representative) to the second (in regards to Edison’s talking machine),
Faber attacked the problem on its physiological side. Quite differently works Mr. Edison: he attacks the problem, not at the source of origin of the vibrations which make articulate speech, but, considering these vibrations as already made, it matters not how, he makes these vibrations impress themselves on a sheet of metallic foil, and then reproduces from these impressions the sonorous vibrations which made them."35
In more sophisticated terms, Scha describes36 two fundamental approaches taken by the developers of voice imitating machines: the genetic method which imitates the physiological processes that generate speech sounds in the human body and the gennematic method which is based on the analysis and reconstruction of speech sounds themselves without considering the way in which the human body produces them. While to proceed from the first methodology to the second generally signifies a better understanding of the mechanism of the phenomenon that we are implementing, sometimes the situation is reversed. In the field of computer vision and other fields of artificial intelligence, gennematic method was the first to emerge. It is only in the 1980s, with the growing popularity of neural networks, there began a shift towards the genetic method - direct imitation of the physiology of the visual system. In a number of laboratories, scientists begin to build artificial eyes which move, focus, and analyze information exactly like human eyes.
What is intriguing, as Scha describes correctly, is that although things generally proceed/progress from the first to the second, there is always this reversal of situation, where we go back from the second to the first. In terms of voice technology, although the shift from conceiving voice as immanently associated with human organ to regarding it as mere sound vibration is taken a progress, it indeed later becomes desirable to treat the speech as a particular form of sound, that is, a voice. Edison is well known for his sensitivity to the particulars of human voice recording (singing, mostly), but his method treats voice as no different from any other acoustic phenomena. Vocoder, however, divides speech into a series of frequency ranges and measures how their spectral characteristics change over time. In other words, instead of recording the voice wholesale, this method actually looks into what there is to record and picks up only the information that is most relevant. Thus, the vocoder dramatically reduces the amount of information needed to store and to transmit speech. In other words, Vocoder’s success lies in treating a voice as a voice.
Consider the various possible ways to record a piano piece. Its most economical rendition, no doubt, is its very notation, which indicates merely the notes to be played, together with highly condensed verbal-emotive instructions such as “fortissimo”. The Edison approach is an acoustic rendering of the piece, complete with the particular sound of the instrument and the effect of architectural acoustics. The vocoder approach is a compromise between the two, it samples the relative strength and time of each note that is being stroked, but it takes into consideration of the particular acoustic behavior of neither the instrument nor the room.
Obviously, when speech is understood as a form of sound and voice treated as no different from other acoustic phenomenon, it also loses its specific (and ontological) connection with the organs that produce it, whether they are live human organs or their manmade counterparts. In this form of speech technology, one can argue, the voice loses its corporeality. Perhaps, looking at the various forms of the desire to locate/fixate a fascination for the voice in the organ that produces it (Kostenbaum’s case comes to mind), it is this loss of corporeality that is most insupportable, unsurpassable as an obstacle to our comprehension – in the age of technologically reproduced voices, what becomes of this organ and where is it located?
Epilogue

I began this paper by suggesting the possibility of regarding a diva’s voice as the product of a superb voice machine. Following this line of thinking, for a diva, to lose a voice signifies not only a temporary or permanent malfunctioning of the voice machine, but an exposure of the mechanical aspect of voice production. In Callas Forever (Franco Zeffirelli, 2002), a retired and reclusive Callas (Fanny Ardant) is cajoled by her former agent Larry Kelly (Jeremy Irons) into a new project, a film version of Carmen that will be shot by Callas in the present day and dubbed with her voice when she still had it. After the initial resistance (always symbolic and perfunctory), the project is accomplished and her career seems to achieve a new height (she has never performed Carmen on stage). The perfect audiovisual synchronization afforded by modern technology (which the film emphatically celebrates) delivers a wonder that I believe no less marvelous than Kempelen’s talking machine was to its audience. However, to the utter perplexity of her agent and the rest of the world, the diva refuses to release the film; in fact, she asks to have it destroyed. Humanism again triumphs over mechanicity. The film ends.
What is it that the diva instinctively recognizes, although she was, like everyone else, very much impressed by the result? That the dubbing damages her professionalism (as the film tries to tell us)? I am willing here to explore the extension of this logic, disregarding the fictitious nature of the story. Callas could not have possibly objected to the fact that her images and sounds are recorded, as is the case in Diva (Jean-Jacques Beineix, 1981). In Diva we have a classical example of the fear of technological reproducibility. As Benjamin put it, “in even the most perfect reproduction, one thing is lacking: the here and now of the work of art—its unique existence in a particular place. It is this unique existence — and nothing else — that bears the mark of the history to which the work has been subject.”37 But if Beineix’s diva shows how the voice can become the perfect fetish object if it denies technological reproducibility, Zeffirelli’s diva does not; and she actually enjoys it, as the film shows us in a scene where she sings along her record wholeheartedly (with only a nightgown and Jeremy Irons peeping, but that’s another story).
What is it then that she cannot accept, with the price of sinking again into her solitary life? Is this another form of the same fetish, just as all claims to authenticity are? Perhaps Benjamin should add one more dimension to his notion of aura, that is, in the age of technological synchronization, what happens to an audiovisual construction that is the human: “In even the most perfect synchronization, one thing is lacking: the indivisible unity of voice and its source. It is this unique combination—and nothing else - that bears the mark of the human to which the work has been subject.”
Does the voice machine shatter this human, or does it create a new one of its own?
Works Cited
Bell, Alexander Graham. “Prehistoric Telephone Days.” National Geographic Magazine XLI, no. 3 (March 1922): 223-241.
Benjamin, Walter. The Work of Art in the Age of Its Technological Reproducibility, and Other Writings on Media. Cambridge, Mass: Belknap Press of Harvard University Press, 2008.
Darwin, Erasmus. The temple of nature: or, The origin of society. A poem, with philosophical notes. Bonsal & Niles, 1804.
Dolar, Mladen. A voice and nothing more. MIT Press, 2006.
Dudley, Homer, and T.H. Tarnoczy. “The Speaking Machine of Wolfgang von Kempelen.” The Journal of the Acoustical Society of America 22, no. 2 (March 1950): 151-166.
Flanagan, J. L. “Voices of Men and Machines.” The Journal of the Acoustical Society of America (1972): 1375-1387.
Flanagan, James L. Speech analysis synthesis and perception. Springer-Verlag, 1972.
Flusser, Vilém. The shape of things: a philosophy of design. Reaktion Books, 1999.
Gitelman, Lisa. Scripts, Grooves, and Writing Machines: Representing Technology in the Edison Era. 1st ed. Stanford University Press, 2000.
Lastra, James. Sound Technology and the American Cinema: Perception, Representation, Modernity. New York: Columbia University Press, 2000.
Mettrie, Julien Offray de La. Man a machine. Open Court, 1912.
Scha, Remko. “Virtual Voices.” MediaMatic 7, no. 2 (1992).
Sobchack, Vivian Carol. Screening space: the American science fiction film. Rutgers University Press, 1997.
Walker, Alexander. Stanley Kubrick directs. Harcourt Brace Jovanovich, 1972.
The voice proclaims a being endowed with sense; only animate bodies sing. It is not the mechanical flutist that plays the flute, but the engineer who measured the flow of air and made the fingers move. ↩︎
Jean-Jacques Rousseau, Essai sur l’origine des langues. ↩︎
Moralia: Sayings of Spartans, in Apophthegmata Laconica. ↩︎
It’s all voice ye are, and nought else. ↩︎
Naturally the Spartans can hardly say the same thing to most divas (or a tenor like Pavarotti)—this may sound like a perverse thought, but I regret that I won’t be able to explorer this motif of gluttony and digestive system to its full extent in this paper. ↩︎
See for example, Bel Canto: A history of vocal pedagogy, by James Stark. ↩︎
Mettrie, Man a machine, 128. ↩︎
Among these two observations, decidedly outrageous at the time, the latter has been proven by evolution theory; and the former by today’s brain science research, whose purpose can be summarized in one phrase that La Mettrie used, “this organization”. ↩︎
Dolar, A voice and nothing more, 8-11. I am unable to confirm since Dolar does not supply a source. ↩︎
Contemporary philosophers such as Daniel Dennett argue that language conditions reasoning. ↩︎
But what made Vaucanson most famous is not his implementation of such a lofty occupation, but his replication of the digestion system. It is perhaps for an obvious reason that he decided this time to build a duck, instead of a human. Maelzel’s trumpet player also refines the design of the flute player. The trumpet player, the Panharmonicon, a giant music box in which the whole orchestra is packed in and a diorama called “the conflagration of Moscow” are often exhibited together with the Turk. ↩︎
Mettrie, Man a machine, 140. ↩︎
For an extremely detailed description of how Kempelen’s machine is operated see Dudley and Tarnoczy, “The Speaking Machine of Wolfgang von Kempelen,” 160-3. ↩︎
Darwin, The temple of nature, 139. This passage is found in the last chapter of a section titled “additional notes” and is preceded by a phonetic analysis of the articulation of sounds in English language. ↩︎
Flanagan, Speech analysis synthesis and perception, 166-7. ↩︎
Bell, “Prehistoric Telephone Days,” 236. ↩︎
Bell told us he later forced a dog to do the same. This dog’s final linguistic accomplishment was to say something that sounds similar to “how are you grandmamma”. ↩︎
John P. Cater, “Electronically Speaking: Computer Speech Generation”, Howard M. Sams & Co., 1983, p. 75. ↩︎
Flanagan, “Voices of Men and Machines,” 1380. ↩︎
Gitelman, Scripts, Grooves, and Writing Machines, 84. ↩︎
Flusser, The shape of things, 95. ↩︎
Or rather, a thousand eyes, like Dr. Mabuse. ↩︎
Sobchack, Screening space, 177. ↩︎
Walker, Stanley Kubrick directs, 258-9. ↩︎
Dolar, A voice and nothing more, 3. ↩︎
Sobchack, Screening space, 181. ↩︎
Bell, “Prehistoric Telephone Days,” 228. ↩︎
Ibid., 231. ↩︎
Dudley and Tarnoczy, “The Speaking Machine of Wolfgang von Kempelen,” 155. ↩︎
Bell, “Prehistoric Telephone Days,” 229. (Note: Changed ‘deal’ to ‘deaf’ based on context of Bell’s work). ↩︎
This rather holistic notation system bears an interesting resemblance to the ancient Chinese notation system for Guqin (a plucked seven string musical instrument), where the finger positions are denoted and then combined into one character that curiously resembles a Chinese character (but in fact is not). One such character is normally divided into four parts: the upper part is for left hand; the lower part for right hand; the upper left for fingering; upper right for chords, and so on. ↩︎
Bell, “Prehistoric Telephone Days,” 232. ↩︎
In Duras’s India Song (1975), the opening scene features an off screen voice of a Laotian beggar woman. Most critics and scholars perceive it as a chant, mainly because the meaning of the words is inaccessible to them. ↩︎
Sonovox was extensively used in radio advertisement in the 1940s and also made its appearance in two Hollywood films, Possessed (1947) and Letter to Three Wives (1949). ↩︎
Lastra, Sound Technology and the American Cinema, 26. ↩︎
Scha, “Virtual Voices,” 33. ↩︎
Benjamin, The Work of Art in the Age of Its Technological Reproducibility, and Other Writings on Media, 21. ↩︎